原码、反码和补码以及溢出
原码、反码和补码以及溢出
符号位
所有有符号整型(支持存入正数、负数 没有使用关键字 unsigned 声明的变量),都必须包含一个符号位,符号位存在于当前变量内存空间的首位,0表示正数 1表示负数
即:
1000 0001 在有符号整型中表示 -1
无符号整型(使用关键字 unsigned 声明的变量),他是没有符号位,在解读 01数据时首位也视为数据位
1000 0001 在无符号整型中表示 129
原码、反码、补码
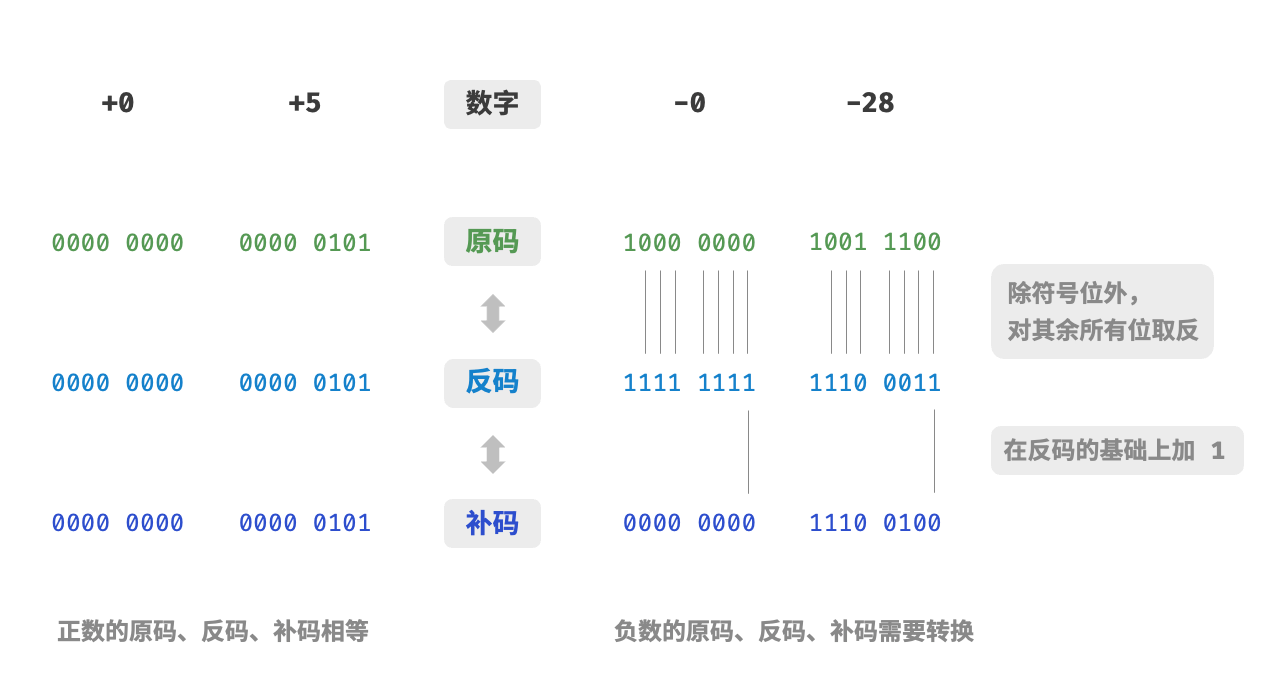
原码:有符号整型 将数字转成二进制,并且数据的首位根据正负指定符号位
+5
原码 0000 0101
-5
原码 1000 0101
反码:正数的反码于原码相同,负数的反码对其除了符号位的每一位取反
+5
原码 0000 0101
反码 0000 0101
-5
原码 1000 0101
反码 1111 1010
补码:正数的补码于原码相同,负数的补码是反码基础上加一
+5
原码 0000 0101
反码 0000 0101
补码 0000 0101
-5
原码 1000 0101
反码 1111 1010
补码 1111 1011
下图就是原码、补码、反码的转换方法:
我们学习过 int,byte 和 char 类型,你可以去百度以上类型的取值范围负数比正数多一个。
int取值范围[-2^31 ; 2^31 -1]char和byte取值范围[-2^7, 2^7-1]即[-128 ~ 127]
真正的原因是正数是以“补码”的形式存储在计算机里的。
总结:
- 原码:计算正数没有任何问题,但是计算负数,+1 的效果就成了 -1 的效果
- 反码:由于原码无法解决计算负数的问题,当遇到负数的时候会将原码转换反码,在计算就会正确的效果了
- 补码:使用反码的时候,0 会有两个码值, 当计算出现跨零的计算是就会出现,差一的问题
原码
原码在计算机中虽然最直观,但是一直存在一些局限性。虽然原码可以表示数字的正负,单不可以直接用于运算
例: 在原码下计算 +1 +(-2) 等于 -3
0000 0001 + 1000 0010 -> 1000 0011
反码
为了解决此问题。计算机引入了反码。
例:使用反码计算 +1 +(-2)可以得到 -1 的反码
+1 原码:0000 0001 反码:0000 0001
-2 原码:1000 0010 反码:1111 1101
相加的反码:1111 1110 原码 1000 0001 等于 -1
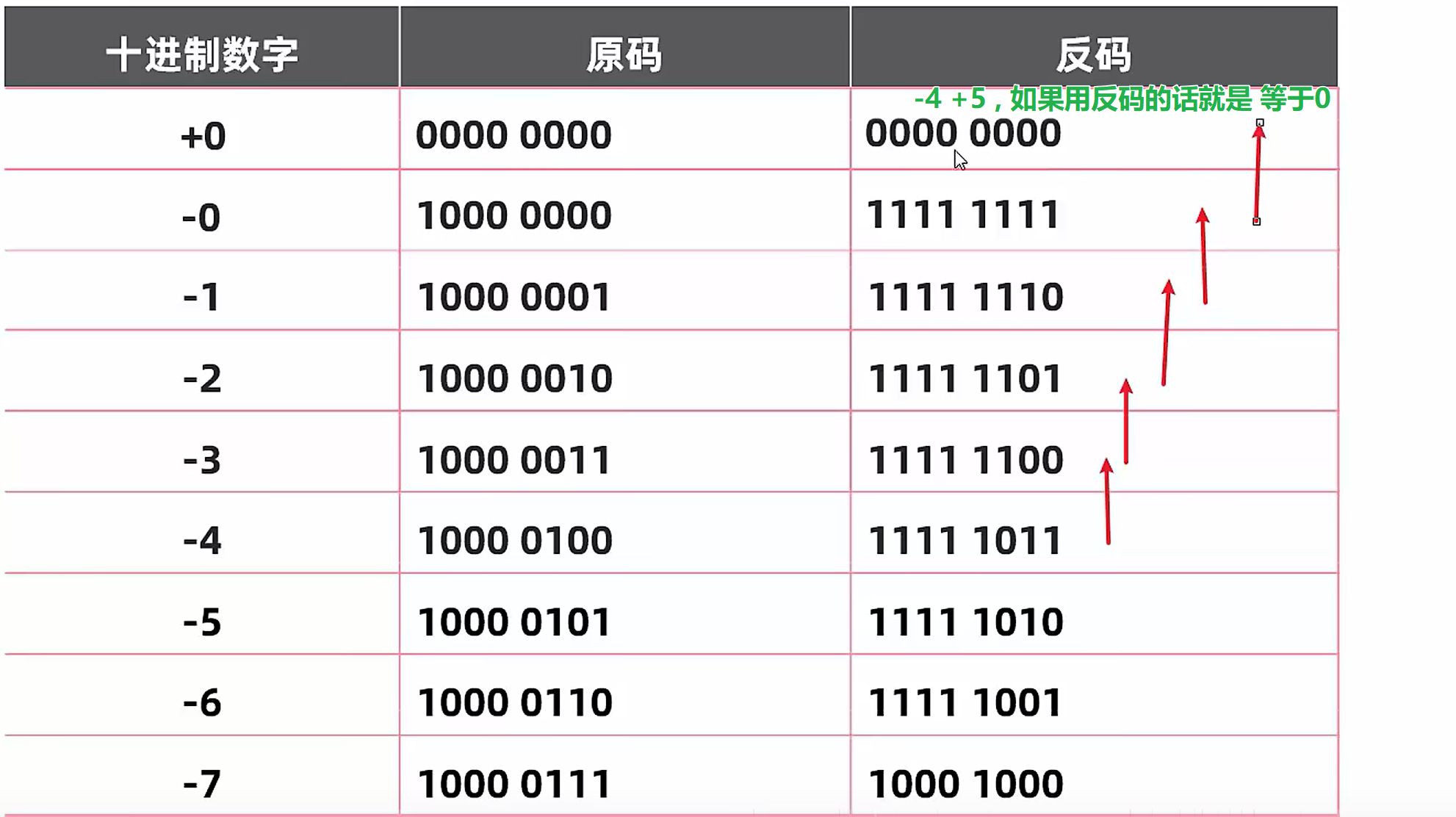
虽然反码可以解决数字运算问题,但是数字零的原码有 +0 和 -0 两种表达方式,反码表达+0和-0分别是 0000 0000, 1111 1111意味着数字零对应两个不同的二进制编码,这可能会带来歧义,比如在条件判断中没有正负之分这就会导致判断结果出错,这时计算机要能识别+0与-0相等需要引入额外的计算,会降低计算机的运算效率。
补码
补码的出现就是在反码的基础上进一步完善二进制编码的运算与判断问题
例
+0 反码 0000 0000 补码 0000 0000
-0 反码 1111 1111 补码 1 0000 0000
在-0的基础上加一,二进制编码会产生进位,但是任何数据类型,因此进位的1溢出了会被舍弃,即 -0 的补码为 0000 0000。这样就意味着+0与-0补码相同,他们两者的歧义问题被解决
+1 + (-2)
+1 补码 0000 0001
-2 补码 1111 1110
补码1111 1111 -> 反码1111 1110 -> 原码1000 0001 -> -1
还剩最后一个疑惑,为什么每个数字的取值范围负数都比正数多1,以 byte为例 [-128,127]?
观察-127 和 +127
+127 原码、反码、补码 0111 1111
-127 原码 1111 1111 反码 1000 0000 补码1000 0001
+126 原码、反码、补码 0111 1110
-126 原码 1111 1110 反码 1000 0001 补码1000 0010
我们发现补码中[-127, 127],[-126,126] 补码都是成对出现,相加后都是 0000 0000,只有 1000 0000是例外并且他没有对应原码,计算机规定这个特殊的补码代表-128。实际上在补码计算中 (-1)+(-127)补码就是 1000 0000
通过原码、反码、补码知识发现一个现象,上述所有操作都是加法运算。这是一个重要的事实:计算机内部硬件电路主要是基于加法运算设计的,因为相对于其他运算(乘、除)加法实现起来更简单。
补码的意义让计算机电路使用加法操作处理正数和负数,无需增加额外的特殊硬件计算减法,乘法等等,并且无需特别处理正负的歧义问题。这样可以大大简化硬件设计,提高运算效率。
记忆:计算机中存储都是补码,人看得都是转换后的原码。
溢出
每种数据类型都有自己的取值范围,取值范围根据数据类型在内存中的大小(字节)去计算,超过数据类型所能表达的范围被称为溢出,溢出的数据位将会被舍弃。
出现溢出原因:
- 将超过范围的数据交给了放不下的数据类型中
- 将大数据类型数据强制转换成小的数据类型。
溢出问题可能导致:
- 两个无符号的正整数相加得到一个负数。
- 两个无符号的正整数相加得到一个非常大的。
#include <stdio.h>
int main(int argc, const char* argv[]) {
// 先根据符号位进行补位操作,如果符号是 1 就补1 ,如果符号是 0 就补 0
// 看需要输出的占位符 ,如果是 %d 就是用部位后的符号为 , 如果是 %u 不用管补位后的符号位,(直接就是正数了)
// 将补码转换为原码(人要做的时 , 机器不用)
unsigned char a = 255; // 1111 1111
char b = 255; // 1111 1111
printf("%d \n", a); // 0000 0000 0000 0000 0000 0000 1111 1111
printf("%u \n", a); // 0000 0000 0000 0000 0000 0000 1111 1111
printf("%d \n", b); // 1111 1111 1111 1111 1111 1111 1111 1111 负数的最大值 -1
printf("%u \n", b); // 1111 1111 1111 1111 1111 1111 1111 1111 int 类型的最大值(无符号)
unsigned short a1 = -1; // 1111 1111 , 1111 1111 65,535
int b1 = a1; // 0000 0000,0000 0000, 1111 1111 , 1111 1111 65,535
printf("%d \n ", a1);
printf("%d \n", b1);
unsigned char a2 = -1; // 1111 1111 255
printf("%d \n", a2); 1111 1111 , 1111 1111 , 1111 1111 , 1111 1110
0000 0000 , 0000 0000 , 0000 0000 , 0000 0001
unsigned int b2 = -1;
printf("%u \n ", b2); // 4294967295
unsigned char a = 256; //127 + 128 = 255
char b = 256;
printf("%d \n", a);
printf("%d \n", b);
return 0;
}
计算溢出问题步骤:
- 先将对应的数据转换对应的补码
- 将补码进行运算(加或者减)
- 看赋值的变量是否是有符号的
- 输出
%d: 赋值的变量是有符号位的按照符号(1 代表负数 0代表整数)进行补位,如果补位后符号是 1 ,就代表这个数是一个负数,需要转换 反码再转换为原码,才能得到正确的数据,如果部位后符号是0 直接计算结果即可%u:赋值的变量是无符号位的按照符号(1 代表负数 0代表整数)进行补位,如果补位后符号是 1 ,直接按照补位后的结果进行即可。

总结:
- 原码:计算正数没有问题(整数的原码、反码、补码都一样的)
- 反码:是用来解决负数运算的问题的
- 补码:用来解决 0 有两个反码的问题导致跨零计算少一的问题。零的另一套编码给负数使用了,这也是导致数据类型中负数的取值范围是正数的取值范围+1 的原因。
- 计算机中存储都是补码 , -128 只有补码(人为规定的)没有反码和原码。
- 溢出问题的解决思路:先部位,后转换