c 语言 数组
数组特点
- 数组中所有的元素数据类型都是一致的
- 数组申请的内存空间是连续的。从低地址到高地址依次连续存放数组中的每个元素。
我们将元素在数组中的位置称为该元素的索引(index)。下图图展示了数组的主要概念和存储方式.
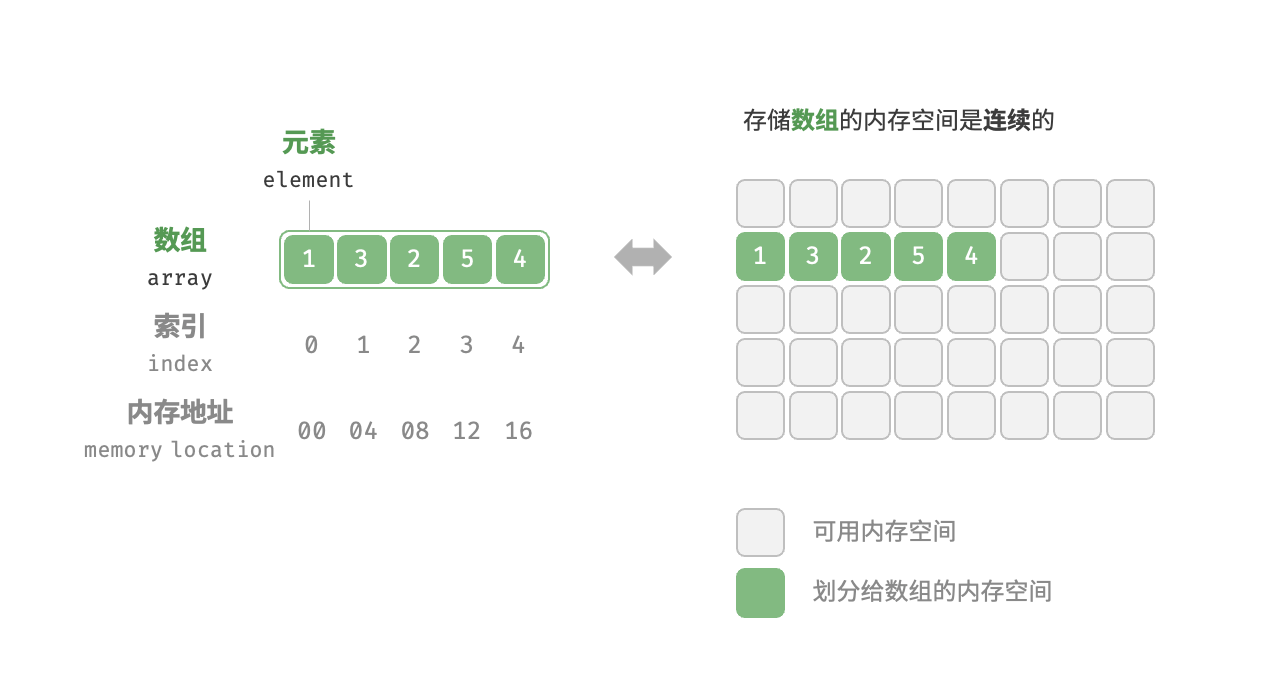
假设有一个int类型的数组arr,其声明如下:
int arr[4] = {0x12345678, 0x9ABCDEF0, 0x13579BDF, 0x2468ACE0};
数组:大小端序只针对数组中元素的字节顺序,不针对数组本身,数组本身是有序从小到大(内存地址)的连续空间。
在小端序系统中,这个数组的内存布局大致如下(注意,这里的地址是假设的,实际地址会根据程序的运行情况而有所不同):
| 索引 | 值(十六进制) | 内存地址(假设) | 字节序(小端序) |
|---|---|---|---|
| 0 | 0x12345678 | 0x1000 | 0x78 0x56 0x34 0x12 |
| 1 | 0x9ABCDEF0 | 0x1004 | 0xF0 0xDE 0xBC 0x9A |
| 2 | 0x13579BDF | 0x1008 | 0xDF 0x9B 0x57 0x13 |
| 3 | 0x2468ACE0 | 0x100C | 0xE0 0xAC 0x68 0x24 |
int arr[3] = { 0x12344520, 0xff004B1C, 0x00553C1E };
int len = sizeof(arr) / sizeof(arr[0]);
for ( int i = 0; i < len; i++ ) {
printf("%p \n", &arr[i]);
}
char* p = arr;
// 0x12344520 , 20 是低位 , 存储在低位 0xffffcbf4 , 小端序:低位对低位 ,高位对高位
printf("%#hhx \n", *p); //0x20
printf("%p \n", p); // 0xffffcbf4
printf("%#hhx \n", *(++p)); // 0x45
printf("%p \n", p); // 0xffffcbf5
printf("%#hhx \n", *(++p)); // 0x34
printf("%p \n", p); // 0xffffcbf6
printf("%#hhx \n", *(++p)); // 0x12
printf("%p \n", p); // 0xffffcbf7
数组的初始化方法
// 正常初始化
int a[5] = {100,200,300,400,500};
int a[5] = {100,200,300,400,500,600}; // 错误,越界了
int a[ ] = {100,200,300}; // OK,自动根据初始化列表分配数组元素个数
int a[5] = {100,200,300}; // OK,只初始化数组元素的一部分
- 赋值的时候,成员之间使用逗号隔开;赋值的成员的数据类型要与数组定义的数据类型一致
- 初始化列表的时候,初始化的数据 个数小于或者等于长度
- 如果是定义的时候初始化了但是初始化列表个数小于数组的大小,那么无论这个数组是全局变量还是局部变量,没有赋值的成员都是为0
- 先定义,没有初始化: 全局变量和静态变量为0,局部变量为随机值
- 数组越界会造成段错异常。
#include <stdio.h>
// 全局变量数组,自动初始化为0
int globalArray[10];
int main() {
// 打印全局数组的内容,应该全部为0
printf("Global array:\n");
for(int i = 0; i < 10; i++) {
printf("%d ", globalArray[i]);
}
printf("\n");
// 局部变量数组,未初始化,将包含随机值
int localArray[10];
// 打印局部变量数组的内容,可能包含任何值
printf("Local array (uninitialized):\n");
for(int i = 0; i < 10; i++) {
printf("%d ", localArray[i]);
}
printf("\n");
// 显式初始化局部变量数组
int initializedLocalArray[10] = {0};
// 打印显式初始化后的局部变量数组的内容,应该全部为0
printf("Local array (initialized):\n");
for(int i = 0; i < 10; i++) {
printf("%d ", initializedLocalArray[i]);
}
printf("\n");
return 0;
}
清空数组
// 使用部分声明其他为零的特性来声明一个全部为零的数组
int arr[10] = { 0 };
变长数组
- 概念:定义时,使用变量作为元素个数的数组。
- 要点:变长数组仅仅指元素个数在定义时是变量,而绝非指数组的长度可长可短。实际上,不管是普通数组还是所谓的变长数组,数组一旦定义完毕,其长度则不可改变。
- 示例:
int len = 5;
int a[len]; // 数组元素个数 len 是变量,因此数组 a 是变长数组
int x = 2;
int y = 3;
int b[x][y]; // 数组元素个数 x、y 是变量,因此数组 b 是变长数组
int b[2][y]; // 数组元素个数 y 是变量,因此数组 b 是变长数组
int b[x][3]; // 数组元素个数 x 是变量,因此数组 b 是变长数组
- 语法:变长数组不可初始化,即以下代码是错误的:
int len = 5;
int a[len] = {1,2,3,4,5}; // 数组 a 不可初始化
变长数组和普通的数组的区别:
- 普通数组实在编译的时候就已经开辟内存空间了 , 编译器
- 变长数组需要等待运算得到具体的结果才会开辟内存空间, , 运行器
- 变长数组只有在 c99 以后编译器才可以使用
- 普通数组性能更好,但是不灵活。
- 变长数组性能比较差,但是灵活
注意点
- 数组一旦确定长度就无法发生改变了
- 数组只有在初始化的可以给整个数组赋值,其他情况下不能个整个数组赋值。(变长数组不行)
- 原因:数组在初始化的数据会跟着数组一起进行对应的内存空间
- 使用赋值符号数组就会退化为首地址。我们无法给首地址进行赋值。
字符数组
概念
字符数组,数组元素是char(字符型)的数组,它可以是一维数组,也可以是二维数组。
定义的时候赋值
char c1[]={'c','h','i','n','a'};
char c2[]={"china"}; // 相当于 char c2[] = "china"; 元素个数为6,默认会在后面加一个'\0'
两者有什么区别?
char c2[]={"china"};
char c2[]={'c','h','i','n','a','\0'};
字符串保存在内存中时会在末尾加一个终止符'\0','\0'的ASCII码就是0。
终止符的作用是用来标志字符串的结束。
开发中都是操作的字符串首个元素的地址,正因为每个字符串都有一个终止符,系统才知道字符串的具体范围。
字符数组名是一个常量,其值为保存的字符串的首地址。
#include <stdio.h>
int main(void)
{
char c1[]={'c','h','i','n','a'};
char c2[]="hello";
printf("c1:%s size:%lu\n",c1,sizeof(c1));
return 0;
}
打印结果:
c1:chinahello size:5
分析:printf 指定 %s的格式 输出 字符串,而字符串默认是以 \0结尾,所以 print f输出一个字符串的时候 要遇到 \0才会停止输出,所以输出c1 的时候,直到遇到c2中的 \0才停止输出。显然,结果不是我们想要的,所以在数组c1中,元素个数应该要多加一个,预留出 \0的位置。
解决方法:
char c1[]={'c','h','i','n','a','\0'};
// 或者char c1[6]={'c','h','i','n','a'};
注意事项
如果字符数组在定义的时候没有赋值,只能通过元素单个赋值或者字符串操作函数进行赋值
char string[6];
string[0] = 'h';
string[1] = 'e';
strcpy(string,"hello");
特别注意:这种写法是错误的
char string[6];
string[6] = "hello";//错误
string = "hello";//也是错误的
原因:数组元素的访问只能是通过单个元素进行的,所以 string[6]是错误的;数组的名字经过编译之后其实就是一个地址,也就是常量(比如可能是 0x00ff110f),所以给一个地址赋值是错误的,string = "hello";//也是错误的

零长数组(需预习:结构体)
概念:长度为0的数组,比如 int data[0];
用途:放在结构体的末尾,作为可变长度数据的入口
示例:
#include <stdio.h>
#include <stdlib.h>
// 只需要理解原理和设计思路
struct person
{
char name[20];
int age;
int friends[0];
};
int main(int argc, char const *argv[])
{
struct person *xiaoming = malloc(sizeof(struct person) + 80); // 20 * 4 多开辟20个元素
struct person *xiaogang = malloc(sizeof(struct person) + 40); // 10 * 4 多开辟10个元素
xiaoming->friends[1] = 777;
xiaoming->friends[19] = 888;
printf("%d \n", xiaoming->friends[1]);
printf("%d \n", xiaoming->friends[19]);
return 0;
}
效果:零长度数组可以根据需要空间进行扩容(越界的扩容)
二维数组
数组声明由:元素类型 数组名 元素数量组成
int a[10]; 表示一个长度为10 每个元素类型为int的数组名为 a
类型 数组名 [长度]
数组内部可以存放任意类型,如果我想创建数组长度为5,存放五个 "int [10]数组"类型,结合以上三要素写出声明如下
int[10] a[5];
// 但是c语言为了美观以及符号优先级问让上面多维数组格式写成下面的形式
int a[5][10];
面试题笔试题开发中遇到复杂多维数组判断其数据类型就将 数组名 元素数量 移除剩下的就是每一项元素的类型
int a[5][10];
移除 a[5] 剩下 int[10] 表示数组a内部元素的类型
int a[5][10]; 在内存中存放的样子

a数组中包含五个元素,每个元素都是一个一维数组,每隔一位数组大小 10 * 4(int) 个字节,里面包含10个int元素
注意很多人理解二维数组都是按n行m列理解,这样理解没问题,但是本质上数组是一个线性存储空间
多维数组初始化
// 完整的初始化
int a[3][4] = {{1,2,3,4},{5,6,7,8},{9,10,11,12}};
// 数组是线性存储的,所以也支持直接按照1维数组形式赋值
int a[3][4] = {1,2,3,4,5,6,7,8,9,10,11,12};
// 部分初始化
int a[3][4] = {0};
int a[3][4] = {1,2,3};
// 省略长度的初始化
int a[][4] = {{1,2,3,4}, {5,6,7,8}}
int a[][4] = {1,2,3,4,5,6,7,8}
// 注意: 第二个中括号的值不能省略, 数组定义长度可以省略编译时会自动给其赋值,
// 第二个中括号时子元素数据类型的一部分是不可省略的
int a[2][] = {{1,2,3,4}, {5,6,7,8}} // 错误,第二个中括号更重要的意思是类型不可省略
总结:
四个一维数组 int arr1[5],int arr2[5],int arr3[5],int arr4[5]
因为上面的四个一维数组长度相同类型相同,我们就可以将这四个一维数组用一个集合表示 int arr[4][5]这个就是一个二维数组
数组遍历
注意在 c 语言中没有对应的方法可以获取数组的长度,但是可以通过公式计算:数组的总字节长度 / 数组数据类型的字节长度 ,通过 sizeof 获取数据的字节长度。
示例:
// 遍历数组
int arr[2] = {1,2};
// 计算数组的长度 = 总的字节长度 / 每一个元素的字节长度
int len = sizeof(arr) / sizeof(arr[0]);
//printf("%d \n ", len);
for (int i = 0; i < len; i++) {
printf("%d \n", arr[i]);
}
使用数组的注意事项
- 当数组作为参数传递是,传递过去的数组的首地址值,长度是2字节 【其实就是一个变量】
- 索引越界异常 , 索引越界了不会报错,但是会访问到错误的数据()
#include <stdio.h>
void printArr(int arr[] , int len) {
for (int i = 0; i < len; i++) {
printf("%d \n", arr[i]);
}
}
int main(){
// 如果需要再 函数中遍历数组,需要再函数的定义处将数据的长度计算好,然后传递下去
int arr[] = { 1,2,3,4,5,5 };
int len = sizeof(arr) / sizeof(arr[0]);
printArr(arr, len);
// 索引越界异常 -858993460 错误的数据
printf("%d \n", arr[9]);
return 0;
}
总结:
- 数组的长度计算公式 : sizeof(总长度) / sizeof(每一个数据的长度)
- 定义出代表完整的数组
- 数组作为形参代表的这个数组的首地址变量。
查找算法:
二分查找:
// 二分查找
// 主要是改变 mid 的值 公式:(max + min ) / 2
int binaryArr(int arr[], int len, int num) {
int max = len - 1;
int min = 0;
int mid = (max + min) / 2;
while (min <= max) {
// 找到了
if (arr[mid] == num) {
return mid;
}
else if (arr[mid] > num) {
// 要找的数据在 左边, 过大了
max = mid - 1;
mid = (max + min) / 2;
}
else if (arr[mid] < num) {
// 要在的数据在 右边 过小了
min = mid + 1;
mid = (max + min) / 2;
}
}
return -1;
}
插值查找
// 插值查找
int interpolationSearch(int arr[], int len, int num) {
int min = 0;
int max = len - 1;
while (min <= max && num >= arr[min] && num <= arr[max]) {
if (arr[max] == arr[min]) {
if (arr[min] == num) return min;
break;
}
int pos = min + ((double)(num - arr[min]) * (max - min)) / (arr[max] - arr[min]);
if (arr[pos] == num) {
return pos;
}
else if (arr[pos] < num) {
min = pos + 1;
}
else if (arr[pos] > num) {
max = pos - 1;
}
}
return -1; // 如果未找到返回-1
}
void reversalArr(int arr[], int len) {
for (int i = 0; i < (len / 2); i++) {
int t = arr[i];
arr[i] = arr[len - i - 1];
arr[len - i - 1] = t;
}
}
注意使用这两个算法的前提数据必须是有序的
排序算法
冒泡排序
void bubblingSort(int arr[], int len) {
for (int i = 0; i < len - 1; i++) {
for (int j = 0; j < len - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
// 交换数据
int t = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = t;
}
}
}
}
选择排序
void selectSort(int arr[], int len) {
for (int i = 0; i < len - 1; i++) {
// 每一轮找出最小值,当每轮确定一个最小值的时候,就不需要那些这个位置的值做比较了,索引这里的开始索引需要 + i
for (int j = 1 + i; j < len; j++) {
//printf("%d --- %d " ,arr[j] , j);
if (arr[i] > arr[j]) {
int t = arr[j];
arr[j] = arr[i];
arr[i] = t;
}
}
}
}
数组名含义
-
在c语言中数组的出现可能有两种含义
- 代表整个数组
- 代表数组的首个元素的地址
-
当出现以下情况时,表示整个数组.其余情况都是首个元素的地址
- 数组定义时
int arr[7] - 使用sizeof运算符
sizeof(arr) - 使用取地址符&时
&arr
- 数组定义时
int arr[] = {1, 2, 3};
printf("%p \n", arr); // 数组首元素的地址
printf("%p", &arr); // 值一样含义不一样,这里值表示的是数组的地址

int arr2[2][3] = {
{ 1, 2, 3 },
{3,4,5}
};
printf("%p \n", &arr2);
printf("%p \n", &arr2[0] + 1 ); // &arr2[0] 获取二维数组中第一个元素的地址 + 1 , 就可以得到下一个二维数组的首地址值
我们可以理解为&获取arr首地址上一级,将其范围扩大 。直接拿着 &数组 +1 就会跳出当前数组。
数组下标运算符
数组下标运算符有两种含义:
- 声明时
int arr[7]表示数组的长度 - 读写时表示地址下标偏移量(索引下标)
arr[2] = 7 ==> *(p + 2) = 7
索引下标便宜有等价写法的
arr[i] = 100
// *解引用符根据地址访问对应内存的值他与 取地址符 & 是一对(正负关系)
*(arr + i) = 100
*(i + arr) = 100
i[arr] = 100 // 这种方式在底层编译器会转换为加地址的形式。,地址 + 偏移量 ,在利用 * 进行解引用 *(地址 + 偏移量 )
int arr[3] = {7, 8, 9};
printf("%d \n", arr[1]); // 8
printf("%d \n", *(arr + 1)); // 8
printf("%d \n", *(1 + arr)); // 8
printf("%d \n", 1[arr]); // 8
总结:
- 数组的名字除了以上三种情况代表首元素地址
- 地址的加减,其实就是地址的偏移,偏移的大小根据当前数据类型(范围)的大小决定
int arr[3] = {7, 8, 9};
printf("%p \n", arr); // 0xffffcc00
printf("%p \n", arr + 1); // 0xffffcc04 范围 4 他是首元素int类型
printf("%p \n", &arr + 1); // 0xffffcc0c 范围扩大编程数组本身 12
- &取地址符,如果后面跟的是变量,取地址符获取的是当前变量所在内存地址,如果他后面跟的是地址,代表扩大地址到上一级类型的范围 ( 比如数组 , &arr ,范围就代表整个数组 )
- *解引用符号,代表缩小一级范围.他跟&是正负关系可以互相抵消,当地址缩小到不能再缩小,就会返回地址里的数据
int arr[3] = {7, 8, 9};
printf("%d \n", *arr); // 7 *(&arr[0])
printf("%p \n", *&arr); // 0xffffcc00
- 万能公式
*(标识符+偏移量) == 标识符[偏移量]
练习:
char str[] = "www.bilibili.com";
1. str地址和&str地址范围
2. 将获取第一个w的方法罗列出来
3. &str+1 跟 &str 相差多少个字节
4. 把获取数据c方法罗列出来
#include <stdio.h>
#include <string.h>
int main(int argc, char const* argv[]) {
char str[] = "www.bilibili.com";
/*
1. str地址和 & str地址范围
2. 将获取第一个w的方法罗列出来
3. & str + 1 跟 & str 相差多少个字节 15
4. 把获取数据c方法罗列出来
*/
char* p1 = str; // 首地址
printf("%p \n", p1);
printf("%p \n", p1 + 1); // 相差一
char (*p2)[16] = &str;
printf("%p \n", p2);
printf("%p \n", p2 + 1); // 相差 16
printf("%c \n", p1[0]);
printf("%c \n", *(p1));
printf("%c \n", (*p2)[0]);
printf("%c \n", *(*p2));
printf("------------\n");
printf("%c \n", p1[13]);
printf("%c \n", *(p1 + 13));
printf("%c \n", (*p2)[13]);
printf("%c \n", *(*p2 + 13));
return 0;
}
字符串操作
atof将字符串转换成浮点型数
头文件: #include <stdlib.h>
定义函数: double atof(const char *nptr);
char a[] = "-100.23";
char b[] = "200e-2";
float c;
c = atof(a) + atof(b);
printf("c=%.2f\n", c);
atoi(将字符串转换成整型数)
头文件 #include <stdlib.h>
定义函数 int atoi(const char *nptr);
char a[] = "-100";
char b[] = "456";
int c;
c = atoi(a) + atoi(b);
printf("c=%d\n", c);
atol(将字符串转换成长整型数)
头文件 #include <stdlib.h>
定义函数 long atol(const char *nptr);
char a[] = "1000000000";
char b[] = " 234567890";
long c;
c = atol(a) + atol(b);
strcat(连接两字符串)
头文件 #include <string.h>
定义函数 char *strcat(char *dest, const char *src);
char a[30] = "string(1)"; // 合并字符串时被合并的字符串大小一定要足够大
char b[] = "string(2)";
printf("before strcat() : %s\n", a);
printf("after strcat() : %s\n", strcat(a, b)); // 返回值时一个新拼接的字符串,同时参数以字符串被拼接了,他的值也是拼接后的结果
printf("after strcat() : %d\n", sizeof(a) );
strcasecmp(忽略大小写比较字符串)
头文件 #include <string.h>
定义函数 int strcasecmp (const char *s1, const char *s2);
若参数 s1 和 s2 字符串相同则返回 0. s1 长度大于 s2 长度则返回大于 0 的值, s1 长度若小于 s2 长
度则返回小于 0 的值.
char a[] = "aBcDeF";
char b[] = "AbCdEf";
if(!strcasecmp(a, b)) // 0为相等
printf("%s=%s\n", a, b);
char a[10] = "aBcDeF";
char b[20] = "AbCdEf";
if (!strcasecmp(a, b)) // 0为相等
printf("%s=%s\n", a, b);
strcmp(比较字符串)
头文件 #include <string.h>
定义函数 int strcmp(const char *s1, const char *s2);
strcmp()用来比较参数 s1 和 s2 字符串. 字符串大小的比较是以 ASCII 码表上的顺序来决定, 此顺序
亦为字符的值. strcmp()首先将 s1 第一个字符值减去 s2 第一个字符值, 若差值为 0 则再继续比较下个字符, 若
差值不为 0 则将差值返回. 例如字符串"Ac"和"ba"比较则会返回字符"A"(65)和'b'(98)的差值(-33).
返回值 若参数 s1 和 s2 字符串相同则返回 0. s1 若大于 s2 则返回大于 0 的值. s1 若小于 s2 则返回小于 0 的
值.
char a[10] = "AbCdEf";
char b[20] = "AbCdEf";
if (!strcmp(a, b)) // 0为相等
printf("%s=%s\n", a, b);
return 0;
strcpy(拷贝字符串)
头文件 #include <string.h>
定义函数 char *strcpy(char *dest, const char *src);
strcpy()会将参数 src 字符串拷贝至参数 dest 所指的地址.
char a[20] = "123";
char b[] = "hello";
printf("%s \n", strcpy(a, b)); // hello
printf("%s \n", a); // hello
strlen(返回字符串长度)
头文件 #include <string.h>
定义函数 size_t strlen (const char *s);
函数说明 strlen()用来计算指定的字符串 s 的长度, 不包括结束字符"\0".
返回值 返回字符串 s 的字符数.
例
/*取得字符串 str 的长度 */
#include <string.h>
main()
{
char *str = "12345678";
printf("str length = %d\n", strlen(str));
}
// 执行 str length = 8
字符串常量
c语言中有一个特殊的常量叫做字符串常量,双引号(")包围的一系列字符。它们在内存中存储为字符数组,并且以空字符('\0')结尾,表示字符串的结束。字符串常量是不可变的,这意味着一旦它们被定义,你就不能修改字符串中的字符。
字符串常量存储在数据段中
printf("%d", sizeof("abcd")); // "abcd"是一个字符串常量代表整个匿名数组
printf("%p", &"abcd");
char *p = "abcd"
p[0] = 'A' // 会报错 "abcd" 是一个常量不可更改

笔记:
段错异常
段错(Segmentation Fault)通常是指程序试图访问或修改它没有权限访问的内存段时发生的错误。这是一个常见的运行时错误,通常会导致程序异常终止。
常见的情况有:
- 访问非法内存地址:比如访问一个空指针,或者已经释放的内存。
- 数组越界:当程序试图访问数组边界之外的元素时。
- 栈溢出:函数调用太深导致栈空间耗尽,或者局部变量使用了过多的栈空间。(递归)
- 写只读内存:尝试修改const变量或者程序代码段。
字符打印异常
#include <stdio.h>
int main(const int argc, const char* argv[]) {
char c2[] = "hello";
char c1[] = { 'c','h','i','n','a' };
// char c2[] = "hello"; 在 ubuntu 中地址的从小到大的。
printf("%p \n", c1);
printf("%p \n", c2);
printf("c1:%s size:%lu\n", c1, sizeof(c1)); // c1:chinahello size:5
return 0;
}
现象:打印c1 字符串吧c2 的也输出了。
涉及都不同的操作系统分配内存的顺序,在 ubuntu 内存从小到大分配, win 中内存从大到小分配,由于 c1 中没有字节串的结束标识导致 c1 访问到下一个内存的东西,下一个内存的地址中的数据。
原因:
- 在 win 中内存地址从大到小分配的 (ubuntu 相反),c2 的内存地址在 c1 后面。
%s打印规则是遇到'\0'才会停止获取 ,%s接收是一个地址。
解释:
- 在打印 c1 打印到最后一个字符时候还是没有看到
'\0'字符串结束标识,就根据最后那个地址接着打印地址对应的字符 ,因为 c2 在 c1 后面并且是连续的所有就会访问到 c2 的数据,在c2 中最后一个字符是'\0'就停止打印了。