IO函数
输入输出方法
IO函数是什么?
- I ---》全称为 Input ---》输入 ---》
scanf()---》从键盘获取一些数值并且存放到内存空间中 - O---》全称为 Output ---》输出 ---》
printf()---》输出某段内存中的数值
也就是说 IO函数 就是 输入输出函数。
注意:这里是从我们自己的程序的角度来看的。
printf函数
printf函数被称为格式化IO函数,因为他是按照指定的格式来操作数据的.
语法:
printf(const char * format, ...);
''
其中 format:就是指定的格式
printf("a = %d\n", a); // 按照 a = %d\n 将 a的值输出
printf("你好\n"); // 将双引号中的你好\n 输出
格式控制符
类似 %d、%f、%u 等等都被成为格式控制符,一个格式控制符就对应一个数据,常见的格式控制符为
%s *字符串格式(数组中)
%d *按照十进制的格式输出(通常用作整型数据 int 中)
%c *按照字符型的格式输出 char
%hd *短整型 short int // h -> half ()
%hhd *字符型的ascii码 char 数据对应的ascii码十进制的值
%hhx *字符的ascii码 ,char 数据对应的 ascii码中十六进制的值
%f *单精度浮点型(实型) float
%lf *单精度浮点型(实型) (用于输入双精度浮点型) double , lf 不用于输出,作用的输入也就是 scanf 函数。
%Lf 单精度浮点型(实型) long double 并不是所有编译器都支持
%ld *long int
%lld long long int
%x *十六进制
%#x *十六进制 并且 十六进制 的前缀 0x也会打印出来
%o *八进制
%#o *八进制 并且 八进制的前缀0打印出来
%e 以科学计数法的方式打印出来
%p *打印内存的地址
%u *无符号整型
打*号的重点记忆
拓展:位宽和小数位设置
%10d或%10#x输出时数字最少占十个文字位,若数字长度小于位宽数字右对齐左边补空格,若数字长度大于位宽则什么都不做%-10d或%-10#x输出时数字最少占十个文字位,因为是负数若数字长度小于位宽数字左对齐右边补空格,若数字长度大于位宽则什么都不做%0.3f表示输出的浮点型小数点后保留3位%10.3f表示数字总位宽位10 数字右对齐,并且小数点后保留3位%-10.3f表示数字总位宽位10 数字左对齐,并且小数点后保留3位
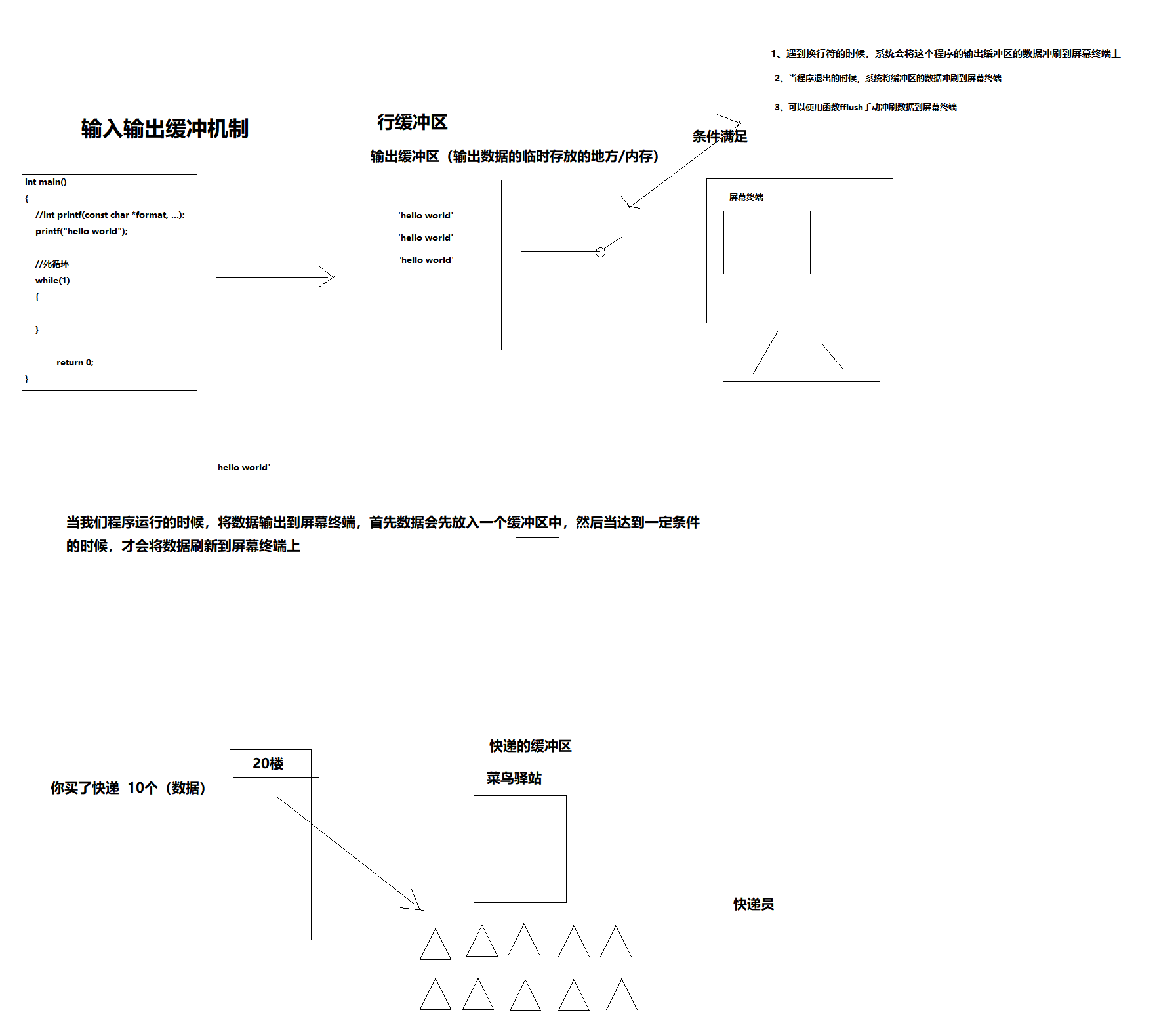
缓冲区
缓冲区又被称为缓存,他是内存的一部分.也就是说在内存中预留一定的存储空间,这些空间用来缓冲输入输出的数据.这个预留的空间就被称为缓冲区.
缓冲区会根据输入设备还是输出设备又分为输入缓冲区 (scanf)和输出缓冲区(printf).
为什么要有缓冲区:
- 减少IO设备的操作
- 提高计算机的运行速度
例如: 我们从磁盘读取信息,先把读出来的数据放在缓冲区,程序再直接去缓冲区中读取数据,缓冲区数据读完后再去磁盘中读取,这样可以减少磁盘读写次数.再加上程序对缓冲区的操作大大快于磁盘操作.所以通过缓冲区可以大大提高计算机运行速度.
在C语言中,标准 I/O 库使用缓冲区来优化文件的读写(stdin标准输入流,stdout标准输出流,stderr错误流).意味着当你使用printf等函数向stdout输出数据时, 首先输出的内容都被存入到一个缓冲区中,而不是直接发送到目标设备。当缓冲区满了或者程序正常结束时缓冲区数据才会被输出到目标设备上。
缓冲区输入或者输出需要满足以下任意条件:
- 程序正常结束
- 缓冲区装满了
缓冲区的类型
全缓冲: 当填满缓冲区之后,才会进行实际IO操作,对磁盘的读写操作。-- windows全缓冲4096字节 Linux 全缓冲 1024 字节
行缓冲:当在输入和输出中遇到换行时,就执行真正IO操作(冲刷缓冲区数据),键盘的输入数据。
不带缓冲:即不进行缓冲,标准错误输出stderr是典型的代表。任何的错误信息可以尽快的显示出来。
#include <stdio.h>
#include <unistd.h>
int main(int argc, const char* argv[]) {
// int a = 10;
// 缓冲区类型:
// - 1. 全缓冲 : 只有当缓存区满了,才会进行输入或者输出
// - 2. 行缓冲 : 遇到换行符就会,行冲刷缓冲区,将缓冲区的中的内容输入或者输出
// - 3. 不带缓冲 : 标准错误输出,原因:错误因该尽早看到尽早错误,所以不应该卡在缓存中
// fprintf 按照模式进行输出
// 标准输出
fprintf(stdout, "out Message \t");
printf("Out Message \t");
// 标准错误输出 (不带缓冲区的)
fprintf(stderr, "Out Messsage Error \t");
perror("Out Message Error \t");
usleep(1000); // 效果 prror 的打印语句比 printf 的语句更早打印
return 0;
}
引发缓冲区刷新
- 输出缓冲区是行缓冲,当遇到换行符时,系统会将缓冲区的数据冲刷到标准输出设备上
- 缓冲区满(溢出)
fflush(刷新哪个缓冲区 { stdout | stdin | stderr }),强制刷新缓冲区。
#include <stdio.h>
#include <unistd.h>
int main(int argc, char const *argv[])
{
printf("hello world");
while ( 1 ) {
sleep(2);
fflush(stdout);
}
return 0;
}
程序正常结束,刷新缓冲
- 当程序退出时,系统将缓冲区的数据冲刷到屏幕终端
return 0结束程序,刷新缓冲区 , return 0 代表程序正常结束exit(0)结束程序,刷新缓冲区 , exit(0) 也是代表进程对应的程序正常结束_exit(0)结束程序,不会处理标准 I/O 缓冲区,更新缓冲区请使用 exit ().
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(int argc, char const *argv[])
{
printf("hello world");
int i = 0;
while ( 1 )
{
sleep(1);
i++;
if(i == 3) {
// fflush(stdout); // fflush 强制刷新缓冲区,不会停止程序
// return 0; // 结束 main = 结束程序 , 正常结束程序也会刷新缓冲区
// exit(0); // exit(0) 结算当前进程,也会刷新缓冲区
_exit(0); // _exit(0) 结束当前进程,但是不会刷新缓冲区。
}
}
return 0;
}
scanf
语法: 定义函数 int scanf(const char * format, ...);
scanf()会将输入的数据根据参数 format 字符串来转换并格式化数据.
#include <stdio.h>
int main()
{
int a1 = 0;
int a2 = 0;
// &a1 取址符,返回当前变量的地址,scanf需要根据变量的地址找到相应的内存,将输入写进对应的内存中
// scanf("%d:%d", &a1, &a2); 这里模板 "%d:%d"输入时需要按照这个格式输入 21:12\n结束
scanf("%d%d", &a1, &a2);
// 输入完毕后缓冲区内还存在一个换行符,下方代码 scanf("%c", &c); %c专门接收字符的不会自动跳过空格和换行
printf("a1 = %d, a2 = %d \n", a1, a2);
char c;
// 输入缓存区内的上一次换行直接赋值给了c 打印的结果 c: 10 \n
scanf("%c", &c);
printf("c: %hhd %c \n", c);
int d;
// %d会自动跳过换行符
scanf("%d", &d);
printf("d: %d \n", d);
return 0;
}
解决用户输入后,输入缓存内部还有一个换行符的问题:
使用 getchar()
函数说明 int getchar()用来从标准输入设备中读取一个字符. 然后将该字符从 unsigned char 转换成 int 后返回.
返回值 getchar()会返回读取到的字符ASCII码值
int n = getchar(); // 清除缓存中的 \n
printf("getchar 的值 %d \n", n);
char c;
// 输入缓存区内的上一次换行直接赋值给了c 打印的结果 c: 10 \n
scanf("%c", &c);
printf("c: %hhd %c \n", c);
scanf 可能出现的问题
例:
#include <stdio.h>
int main(int argc, char const *argv[])
{
// 若用户的输入不是一个数字, scanf("%d", &a); 会因为没有拿到想要的整型数据而退出
// 但是你输入得字符还在缓冲区中, 第二个 scanf("%d", &b); 又去缓冲区拿发现仍然不是想要的数据继续退出
// 输入得字符还在缓冲区中
int a = 0, b = 0;
// 例输入了一个逗号
scanf("%d", &a);
scanf("%d", &b);
printf("a=%d, b=%d", a, b); // 0 0
int c = getchar(); // 拿到 逗号,
printf("c = %c", c); // ,
int d = getchar(); // 拿到换行
printf("c = %d %c", d, d);
return 0;
}
scanf("%d", &a);输入 123abcd 会把 123读出来scanf("%d", &a);输入 12.34 会把 12读出来
拓展: scanf 读字符串,遇到空格就会停下,也就是说 scanf 读字符串 其实读的是单词, 如何实现scanf读一整个句子(遇到\n换行符才停止)- 利用 [^ 符号] ,来指定遇到什么符号后停止接收缓冲区中的数据。
char str[100];
// scanf("%s", str); // 读取空格就会停止接收
// scanf("%[^\n]", str); // 读到换行符才停止接收
scanf("%[^.]", str); // 读到 . 符号停止接收
printf("%s\n", str);
注意: printf 和 scanf 切换使用时,会自动刷新缓冲区
#include <stdio.h>
int main(int argc, char const *argv[])
{
printf("hello world");
while ( 1 ) {
sleep(2);
int a = 0;
scanf("%d", a);
}
return 0;
}
注意点:
- scanf 第一个函数代表的输入的格式,如果设置的格式输入才能正常接收。
- scanf 中接收 double ,需要使用
%lf, 才能正确的接收到数据。 %d作为占位符只会接收数值,如果是其他字符会忽略掉%c作为占位符可以接收任意字符。
字节顺序(大小端)
虽然数据包的大小对了,但是数据包里的字段还存在一个问题 —— 字节顺序。
如果数组的话:只针对数组中元素的字节顺序,不针对数组本身,数组本身是有序从小到大(内存地址) 的连续空间。
字节顺序又称“大小端”问题,是指多字节类型的数据在内存中的存放顺序。简单来说就是:到底是先存放高字节数据,还是先存放低字节数据?
- 小端字节序(Little-endian):低字节数据存放在内存低地址处,高字节数据存放在内存的高地址处;
- 大端字节序(Big-endian):高字节数据存放在内存低地址处,低字节数据存放在内存的高地址处。
例如,一个值为 0x0A0B0C0D 的整型数,采用小端序和大端序时在内存中的存储情况如下图所示。
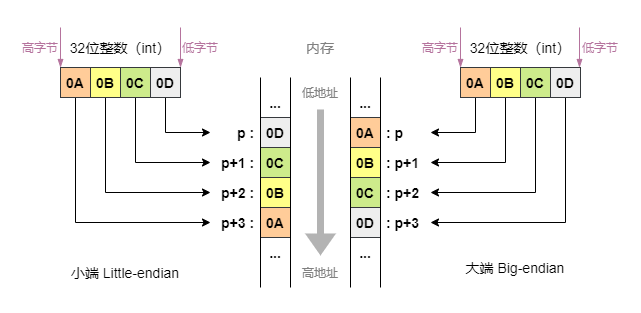
- 字节从后往前排高低
- 地址根据地址大小排高低。
在现代计算机系统中,字节顺序可以由 CPU、操作系统或者编译器来决定。因此在网络数据传输中,也需要注意字节顺序的问题,这样才能保证在网络中传输的字节流与协议中规定的顺序一致,保证不同平台产品的互通。
大小端的争吵从十八世纪就开始了,小说《格列佛游记》中描述到,小人国为水煮蛋该从大的一端(Big-End)剥开还是小的一端(Little-End)剥开而争论,争论的双方分别被称为“大端派”和“小端派”。
为了解决这个纷争,TCP/IP 协议中规定了网络字节序为大端序,从而保证数据在网络中传输的一致性。因此在程序中发数据包时,对于多字节数据,需要将主机字节序转换为网络字节序。同样,接收数据包的一端则要将网络字节序转换为主机字节序。
实际上,POSIX 标准 C 库函数中已经提供了相关的转换函数,包括 htonl、htons、ntohl 和 ntohs 四个 API。
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostlong);
uint16_t htons(uint16_t hostshort);
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);
另外 endian.h 中还定义了更通用的 16、32、64 字节数据的大小端转换函数,包括 htobe16、htole16、be16toh、le16toh、htobe32、htole32、be32toh、le32toh、htobe64、htole64、be64toh、le64toh 等一组函数。
uint16_t htobe16(uint16_t host_16bits);
uint16_t htole16(uint16_t host_16bits);
uint16_t be16toh(uint16_t big_endian_16bits);
uint16_t le16toh(uint16_t little_endian_16bits);
uint32_t htobe32(uint32_t host_32bits);
uint32_t htole32(uint32_t host_32bits);
uint32_t be32toh(uint32_t big_endian_32bits);
uint32_t le32toh(uint32_t little_endian_32bits);
uint64_t htobe64(uint64_t host_64bits);
uint64_t htole64(uint64_t host_64bits);
uint64_t be64toh(uint64_t big_endian_64bits);
uint64_t le64toh(uint64_t little_endian_64bits);
man 帮助手册
在编程开发中,需要很多系统指令、函数、数据类型等等,种类繁多。这是可以通过man帮助手册查阅相关的使用方法。
man 是最权威的
man文档分为9册:
- shell 命令( 默认安装)
- 系统调用
- 库函数
- 特殊文件
- 文件特殊格式或协定
- 等等
安装man手册
默认情况下 Linux 只安装第一册,其他都需要自己手动安装
$ sudo apt install manpages
$ sudo apt install manpages-dev
$ sudo apt install manpages-posix
$ sudo apt install manpages-posix-dev
查询满手册
先查看要查询的方法的分册
$ man -k printf # 将 printf 作为关键字查询,所有包含该关键字的方法有可能查到 snprintf
$ man -f printf # 只查询名叫 printf 的方法
查询结果
printf (3) - formatted output conversion
printf (1) - format and print data
这样你就可以根据后面描述找到需要查询哪一册,指定册查询
man 3 printf